
Abstract
Learning robot manipulation policies with deep neural networks from a single demonstration remains highly challenging, as even small deviations from the demonstrated trajectory can quickly compound into failure, while collecting substantial online interaction data is costly. We propose ReGIL, a retrieval-guided imitation learning framework that treats a single demonstration as an external memory. ReGIL repeatedly queries this static memory throughout training to simultaneously guide exploration, generate the regularization buffer, and construct rewards. Specifically, it computes rewards through local temporal alignment between the current trajectory and the retrieved segment, providing step-wise and informative feedback for policy improvement. We evaluate ReGIL on robotic manipulation tasks from the LIBERO and Meta-World benchmarks under the single demonstration setting. ReGIL outperforms prior baselines in both success rate and training efficiency. In real-robot experiments, using only one demonstration and less than one hour of online training, ReGIL achieves over 75% success rate across three manipulation tasks with randomness in both initial robot pose and target position. These results demonstrate that leveraging the single demonstration as reusable memory can provide more than static supervision for efficient robot learning.
Method
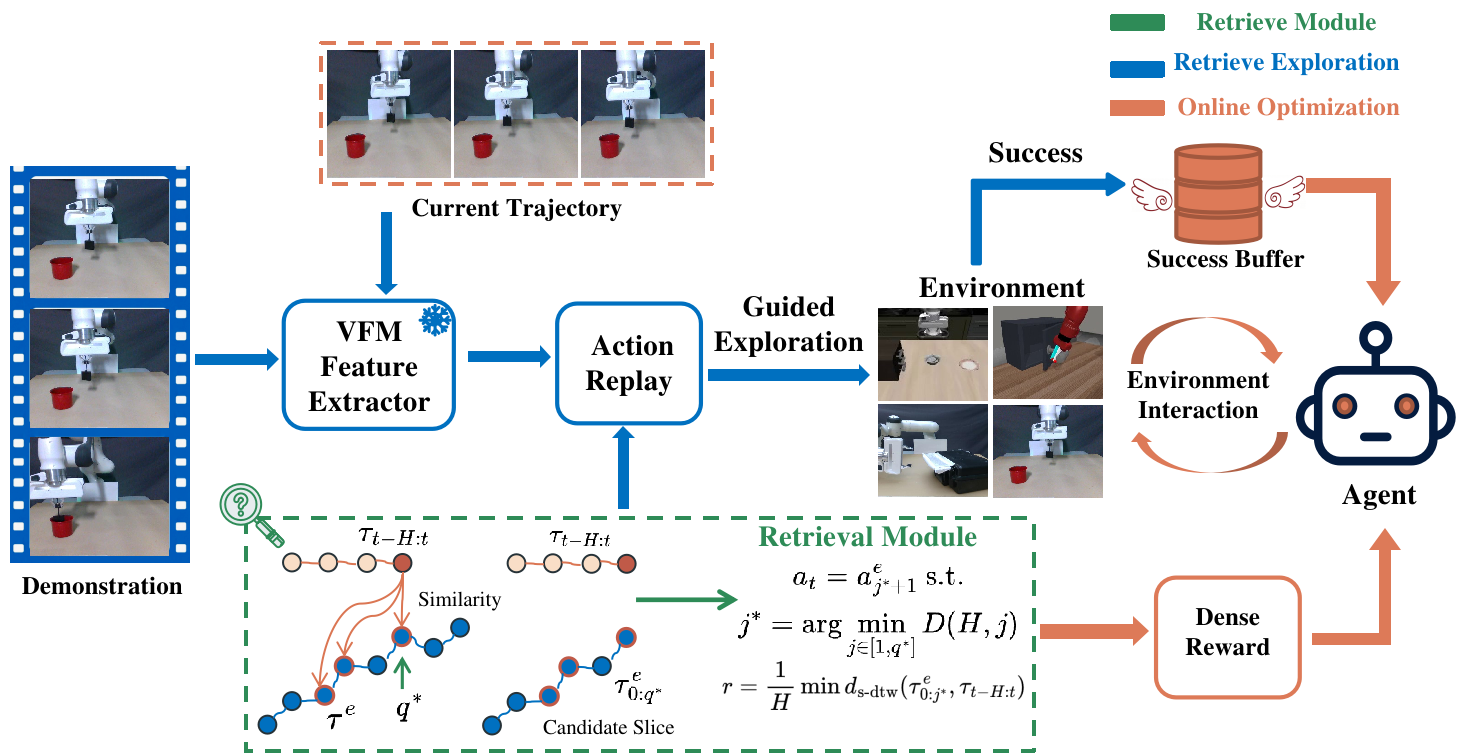
ReGIL begins with a retrieval-and-replay exploration phase. A Vision Foundation Model (VFM) extracts visual features from both the agent’s current trajectories and the expert demonstration to retrieve task-relevant expert segments. These retrieved segments are used for action replay during the early exploration and similarity-based reward shaping throughout the whole process, providing dense reward signals for learning. During the online optimization phase, the policy is updated through environment interaction using the retrieval-based rewards together with a decaying imitation regularization term.
Experimental Result
We evaluate our approach in both simulation and real world under one demonstration setting to evaluate ReGIL.
Simulation
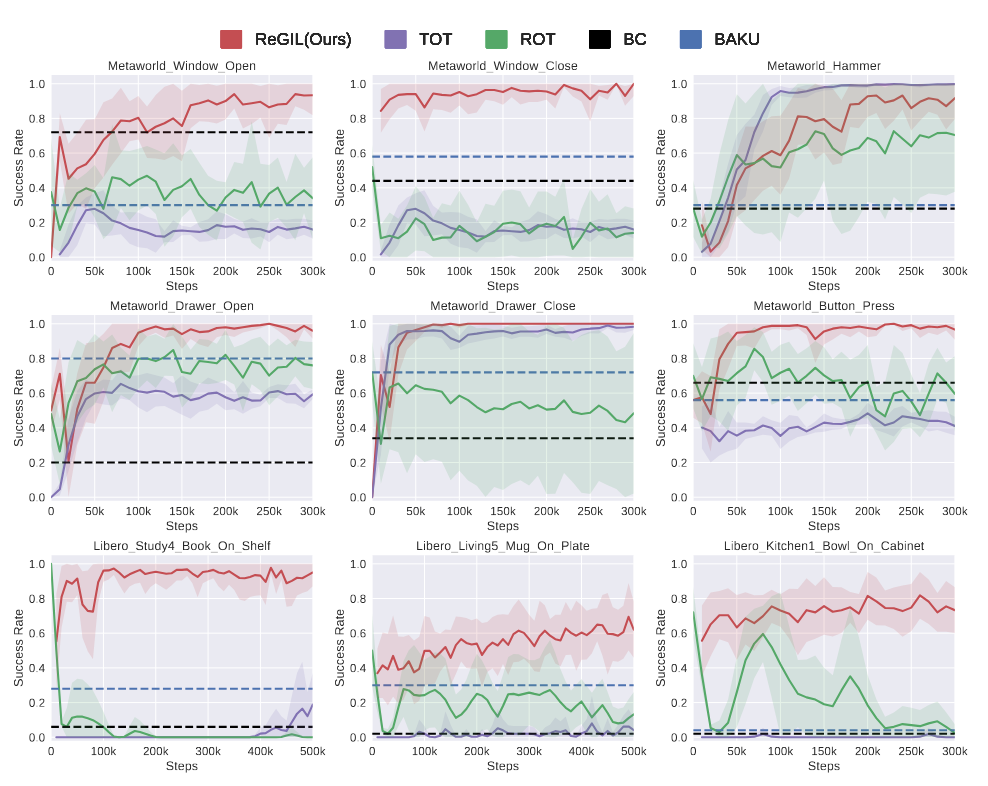
In simulation,we evaluate our approach on both Meta-World and LIBERO task suites. We report the mean and standard deviation of the success rate across 5 random seeds for online methods, while report the average success rate for offline methods for 50 trials.
Baseline comprision
Ablation Study
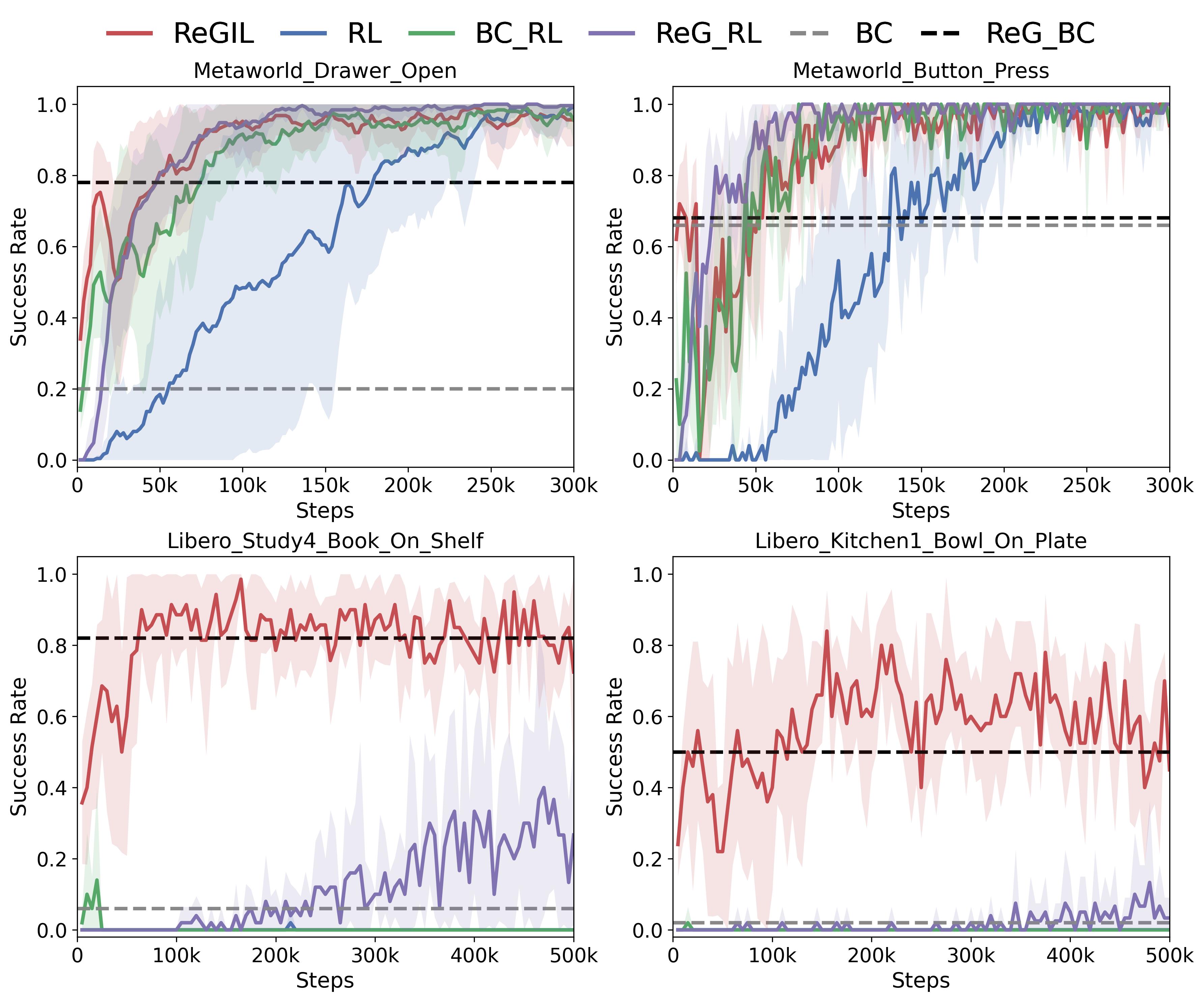
Component Ablation Study Result
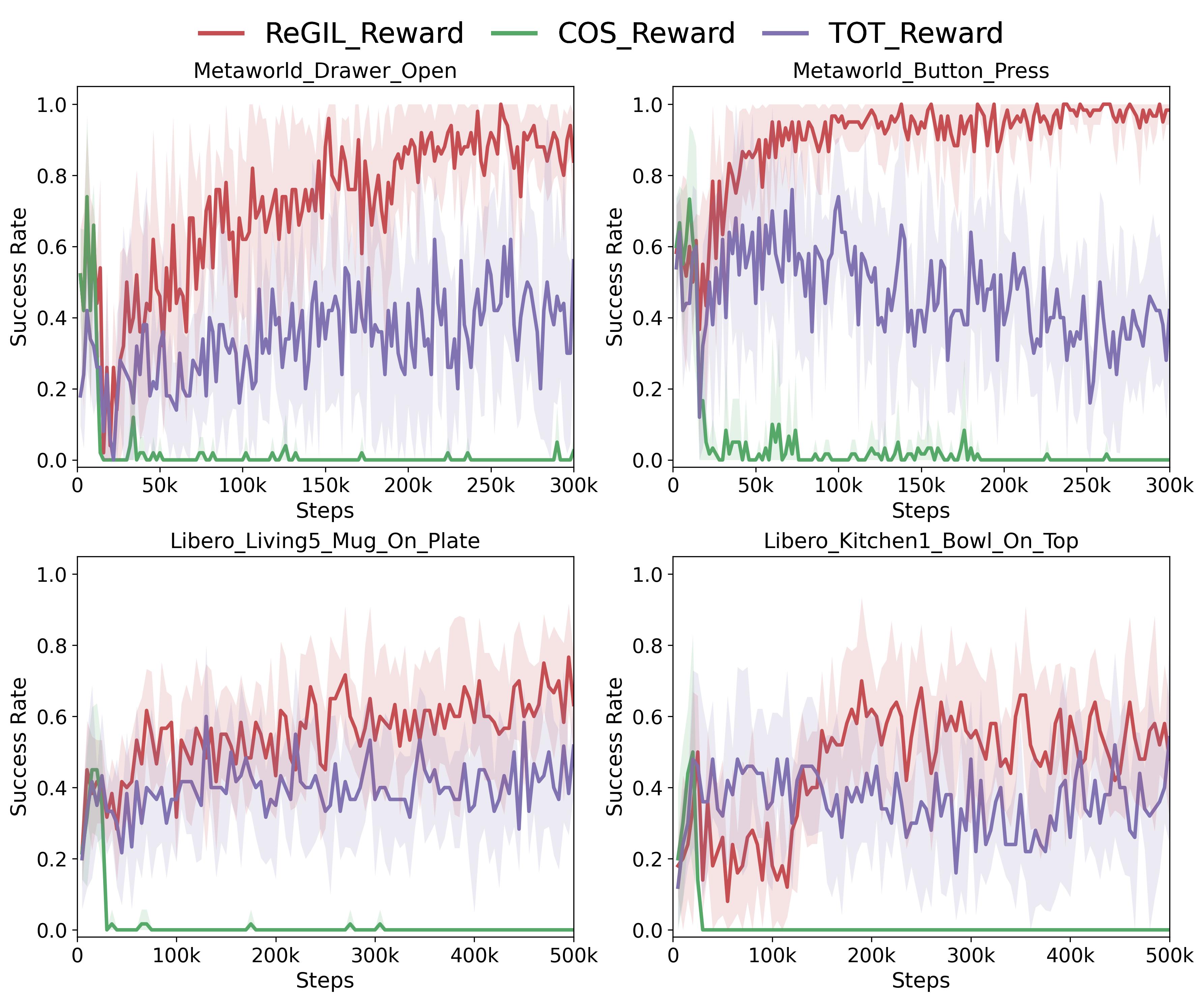
Reward Ablation Study Result
Real Robot
We evaluate our method on three real-world tasks using a Franka Emika Panda manipulator: (1) Reach (a fundamental positioning task), (2) Insert (requiring high precision), and (3) Open(involving rich-contact dynamics)
Demonstration
Reach
Insert
Open
Fixed Target
BC
BC_RL
ReG_BC
ReGIL
Task: Reach
BC
BC_RL
ReG_BC
ReGIL
Task: Insert
BC
BC_RL
ReG_BC
ReGIL
Task: Open
Random Target
BC
BC_RL
ReG_BC
ReGIL
Task: Reach
BC
BC_RL
ReG_BC
ReGIL
Task: Insert
BC
BC_RL
ReG_BC
ReGIL
Task: Open
Failure Cases
Reach
Insert
Open
Additional Analysis
Sensitivity Study on Retrieval Parameters
Table: Effects of Temporal Stride(H),Candidate size(k), and Vision Encoder Selection.
| Benchmark | History (H) [k=5] | Candidate number (k) [H=5] | Encoder [k=5, H=5] | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| H=10 | H=5 | H=3 | k=10 | k=5 | k=3 | k=1 | CLIP | DINO | R3M | |
| MetaWorld | 0.48 | 0.53 | 0.46 | 0.53 | 0.53 | 0.50 | 0.48 | 0.475 | 0.53 | 0.45 |
| LIBERO | 0.50 | 0.47 | 0.42 | 0.47 | 0.47 | 0.50 | 0.37 | 0.017 | 0.47 | 0.17 |
| Mean | 0.49 | 0.50 | 0.44 | 0.50 | 0.50 | 0.50 | 0.425 | 0.246 | 0.50 | 0.31 |
Computational Efficiency Analysis
Table: Latency Breakdown and Computational Efficiency.
| Task | Total Pipeline Cost (ms) | Breakdown Cost (ms) & Ratio | Max Control Freq. (Hz) | |
|---|---|---|---|---|
| Pure DINO Encoding | Pure Search + S-DTW | |||
| MetaWorld | 31.61 ± 2.17 | 30.30 ± 1.84 (95.9%) | 1.29 ± 0.43 (4.1%) | 31.64 |
| LIBERO | 31.07 ± 1.04 | 29.61 ± 1.02 (95.3%) | 1.44 ± 0.05 (4.6%) | 32.18 |
| Real Insert | 32.85 ± 4.64 | 30.56 ± 3.22 (93.0%) | 2.26 ± 2.38 (6.9%) | 30.45 |
| Real Reach | 31.94 ± 3.92 | 30.09 ± 3.82 (94.2%) | 1.83 ± 0.21 (5.7%) | 31.31 |
| Real Open | 31.44 ± 1.32 | 29.32 ± 1.29 (93.3%) | 2.09 ± 0.21 (6.7%) | 31.81 |
Success Buffer Size Across Tasks
Table: Mean and standard deviation of samples collected in the success buffer. Maximum capacity is indicated in parentheses.
| Environment | Suite (Maximum) | Task Name | Success Buffer Size (Mean ± Std) |
|---|---|---|---|
| Simulation | MetaWorld (5000) |
button_press | 1716.00 ± 266.17 |
| door_open | 2841.50 ± 674.94 | ||
| drawer_close | 3222.80 ± 244.98 | ||
| drawer_open | 2301.00 ± 243.07 | ||
| hammer | 455.83 ± 146.58 | ||
| window_close | 3031.20 ± 544.19 | ||
| window_open | 1807.60 ± 500.73 | ||
| Simulation | LIBERO (10000) |
kitchen1_bowl_on_cabinet | 9897.83 ± 34.32 |
| kitchen1_drawer | 9915.80 ± 22.56 | ||
| kitchen1_bowl_on_plate | 3023.83 ± 973.09 | ||
| kitchen2_bowl_on_plate | 7505.67 ± 959.24 | ||
| living5_mug_on_plate | 6228.40 ± 765.61 | ||
| study4 | 9961.17 ± 25.16 | ||
| Real World | (1000) | reach | 814.00 |
| (1300) | insert | 961.00 | |
| (1300) | open | 947.00 |
Success Buffer Qualitative Analysis
Task Trajectories Visualization
K1_Bowl_on_Cabinet
K2_Bowl_on_Plate
K1_Bowl_on_Plate
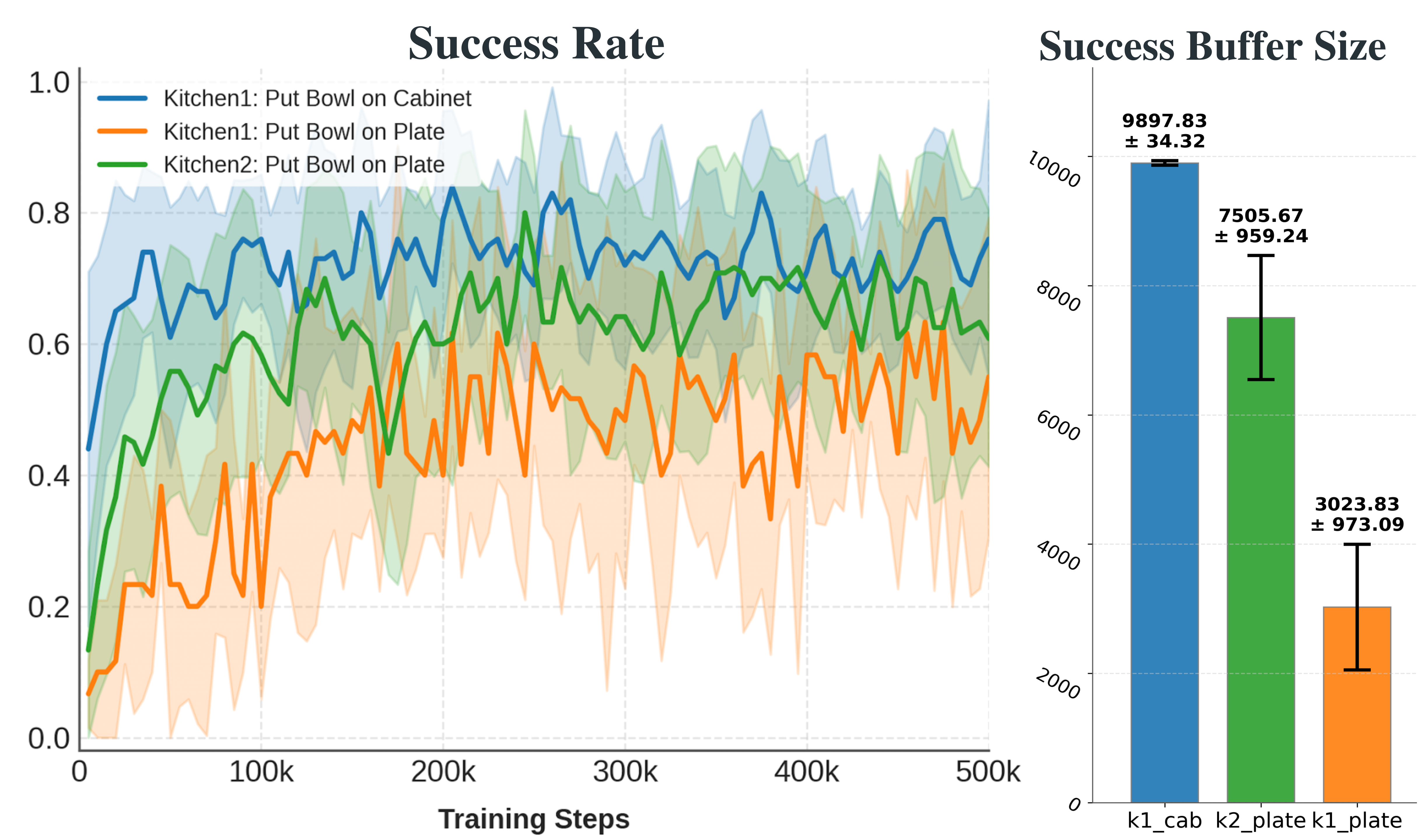
Training performance comparison across three similar kitchen manipulation tasks. Left: Success rates across 5 runs, and the shaded regions indicate the standard deviation. Right: Average success buffer size collected during training.
BibTeX
@article{YourPaperKey2024,
title={ReGIL: Retrieval-Guided Imitation Learning from a Single Demonstration},
author={First Author and Second Author and Third Author},
journal={Conference/Journal Name},
year={2026},
url={https://regil2026.github.io}
}